一般化カテゴリ発見
Generalized Category Discovery
- https://arxiv.org/abs/2201.02609
- 2022/01
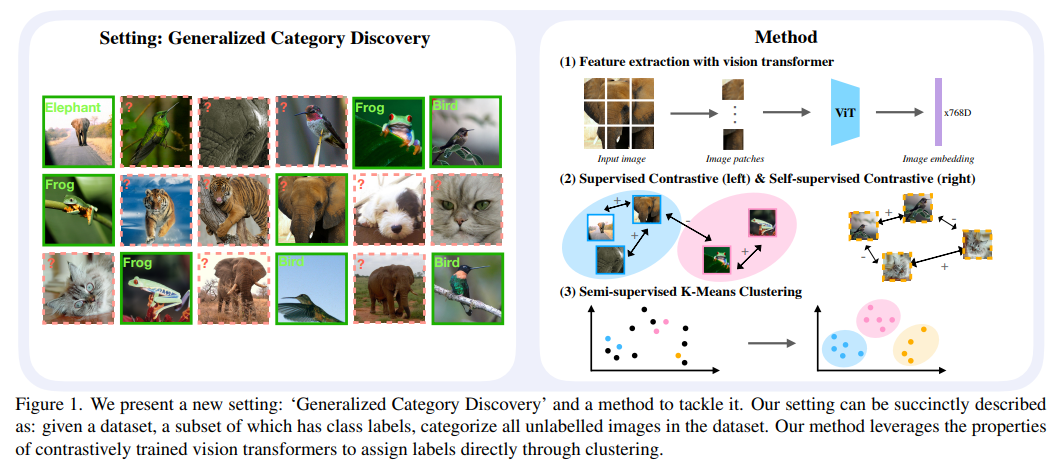

- 一般化カテゴリ発見というタスクを提案
- ラベル付けされた画像集合とされていない画像集合から、ラベルなし集合の全画像を分類するタスク.ラベルなし画像は既存カテゴリor新規カテゴリに属する
- 新規カテゴリ発見(NCD)というタスクは存在したが,ラベルなし画像はすべて新規カテゴリから来ると仮定していた
- NCDの代表手法をベースに提案タスクをvitバックボーンで学習し,分類ヘッドが過適合することを発見
- パラメトリック分類器を排除してk-meansと対比学習を利用したモデルを提案
- ViTモデルを対比的に学習し,特徴空間でクラスタリングを行う
- オンライン学習には対応していない
- ラベルなしデータでカテゴリ数を推定する方法を提案
モバイルUI要素に説明を付与する widget captioning
Widget Captioning: Generating Natural Language Description for Mobile User Interface Elements
- https://arxiv.org/abs/2010.04295
- EMNLP 2020


- android App UIの要素に説明を付与するタスク, widget captioningを提案
- CNN+transformerでimageとview hierarchyを入力してキャプション生成するtransformerベースのモデルを提案
- ablationで提案手法の有効性を示している.指標はevalcococapのBLUE1,2, R, C, M, SでBLEU2=32.2など.人間による評価も行いfull modelに対する支持率は78.64%
- dataはRICOベースのandroid UIデータを人間がキャプション付与(6,470のアプリの21,750画面にわたる61,285のUI要素に対して、162,859のキャプション)
- caption長さは平均2.72で非常に短い.述語+目的語の形式が多い
Attentionのみのモデルで翻訳タスク大幅改善, Transformer
Attention Is All You Need
- https://arxiv.org/abs/1706.03762
- 2017/06, NeurIPS 2017


- RNNもCNNも使用せずattentionによりWMT2014英->独 翻訳で28.4BLEU達成.前のsotaから2ポイント改善
- RNNは自己回帰のため1サンプル内での並列化は不可能(かつ系列長が異なるサンプルのbatch化も困難).提案手法は1サンプル内では全部のtokenを並列に処理するため高速
- self attentionでは入力をQuery, Key, Valueに変換し,Qの一つのベクトルと,K全部の内積を計算, 正規化してsoftmaxしてVの重要度を示す重みを求める.(実際はQを行列としてその全部のベクトルに対してこれを計算)
- 単一のattention計算の代わりにQ,K,Vをそれぞれ小さい次元に分割してattn計算し,結果を結合して射影するmulti head attentionを導入すると有益(newstest2013の英->独 翻訳で検証)
- RNNではtoken入力の順番が位置情報を提供しているが,提案手法では位置エンコーディングとしてtokenに位置に応じたサイン/コサイン関数ベースの値を加算する.learnableな埋め込みを使用した実験も行い,sinのほうが長いシーケンスに外挿するとしている
- 長期依存性をモデリングする効率に関して,自己アテンション層は定数の逐次実行操作で全ての位置を結ぶが、リカレント層はO(n)の逐次実行操作を必要など.提案手法が効率的
長文に強い相対位置埋め込みを持つモデル RoFormer
RoFormer: Enhanced Transformer with Rotary Position Embedding
- https://arxiv.org/abs/2104.09864
- 2021/04

クロスモーダル事前学習不要のVQAモデル, Multimodal Bitransformer
Supervised Multimodal Bitransformers for Classifying Images and Text

- VQAにおいて,個別に事前学習済みの画像encoder, text encoderを組み合わせてBERTベースモデルでSAすることで,VilBERTのようなクロスモーダル事前学習モデルに匹敵する性能が出る
- 学習済みモデルの凍結を解除するタイミングについてablationを実施し,画像エンコーダの早期凍結解除は最も効果的としている
Jigsaw: 大規模言語モデルのコード生成に前/後処理を追加し精度改善
Jigsaw: Large Language Models meet Program Synthesis
https://arxiv.org/abs/2112.02969
ICSE'22, 2021/12/06
- 大規模事前学習言語モデル(GPT-3, Codex.PTLMと呼ぶ)は自然言語からコード生成可能であるが,変数名変換とAST-to-AST変換による後処理モジュールを追加して生成コード(Pandas)の品質を向上さるJigsawを提案


モデル
- 入力は自然言語記述とテストケース(入出力例)
- モデルはPTLMをブラックボックスとして使用し,後処理ではAPI関数と引数の組み合わせ検索, PTMLの出力を修正する変換ルールの学習/更新を行う
- 変数名の変換, 引数の変換についてはAutopandasツール(9)で使用されているアプローチを採用(GNN).PTLMの出力から自然言語によるクエリでメソッド名を抽出しデータを集め,学習.Autopandasのジェネレータを拡張し、リストや辞書のような複雑なデータ型を考慮し、考慮するAPIのセットを拡張
- 演算子や括弧の付与に関してはAST-to-ASTの変換(BluePencil(26)ベース)で対応する
- 前処理として,コンテキストバンクから現在のクエリに類似した要素を選び,PTLMへ与えるコンテキストに追加する.類似性はtf-idf及びtransformerで算出する.コンテキストバンクは更新される
データ
- 2つのデータセットを作成( PandasEval1 68個のPython Pandasタスク, PandasEval2 21のPandasタスク 25人のユーザと2回のセッションで実施したハッカソンで、図解として提示)
評価
vision分野で多様な下流タスクに適用できる基礎モデルFlorence
Florence: A New Foundation Model for Computer Vision 2021/11/22
https://arxiv.org/abs/2111.11432
