単語埋め込みによる分散表現の学習を提案した論文を読んだ
言語処理関係の深層学習モデルでは,単語埋め込みを言語モデルと同時に学習する手法をよく使用するが,それを最初に提案した論文だと思う.
wikipediaで単語埋め込みの項を見ていて,今日的な形の手法で最初のはこれのようだった.違っていたらご指摘ください. https://en.wikipedia.org/wiki/Word_embedding#Development_and_history_of_the_approach
NeurIPS(2000)版もある(未読) https://papers.nips.cc/paper/2000/hash/728f206c2a01bf572b5940d7d9a8fa4c-Abstract.html
A Neural Probabilistic Language Model
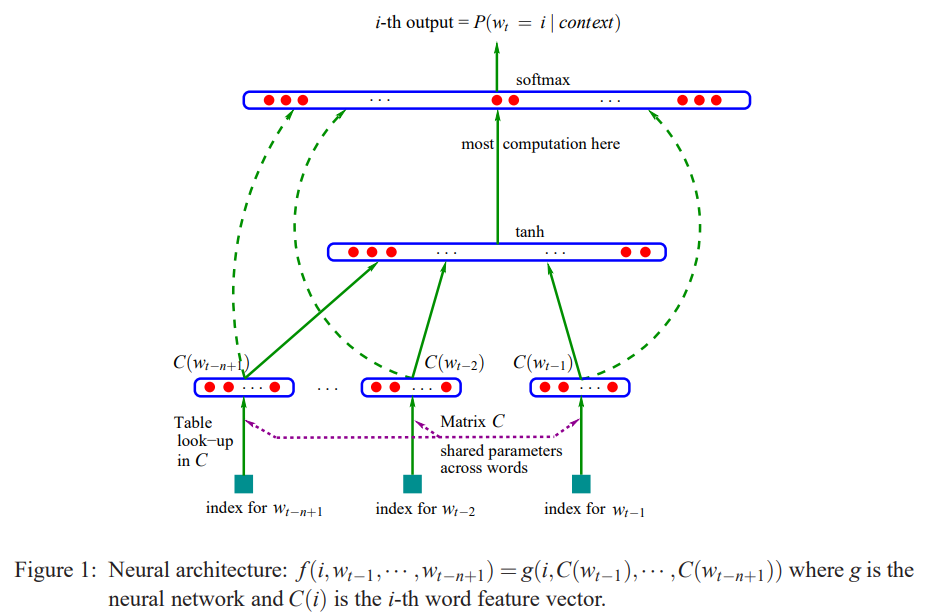
- 単語の分散表現を埋め込み行列とし,言語モデル(単語の結合確率)と同時に学習する方法を提案,当時sotaの平滑化trigramモデルより10%~20%優れたperplexity を達成
- この手法は以下のようにまとめられる
- 語彙の各単語に実数の特徴ベクトルを割り当て
- 語彙列の結合確率を上記の特徴ベクトルで表現する
- 上記語彙特徴ベクトルと,確率関数のパラメタを同時に学習
- 語彙の特徴ベクトルはV行m列の行列で表現され,Vは語彙数, mは次元数.
- 学習は正則化つき対数尤度最大化で,出力はsoftmaxで単語確率を出力しておりそこは分散ベクトルではない.分散ベクトルを出力する場合は語彙にない単語を表現できることにも言及
- MPIを使ったCPU上での並列計算(forward, backward)を実装している(データ並列, パラメタ並列)
- 単語を意味空間の1点に割り当てるため多義語ではうまく動作しないと予想している