ニュース記事・画像からキャプション生成,Transform and Tell
Transform and Tell: Entity-Aware News Image Captioning
- paper
- https://arxiv.org/abs/2012.00364
- Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, Wen Gao
- github
- データセット
- GoodNews, NYTimes800k
- project
まとめ
- どんなもの?
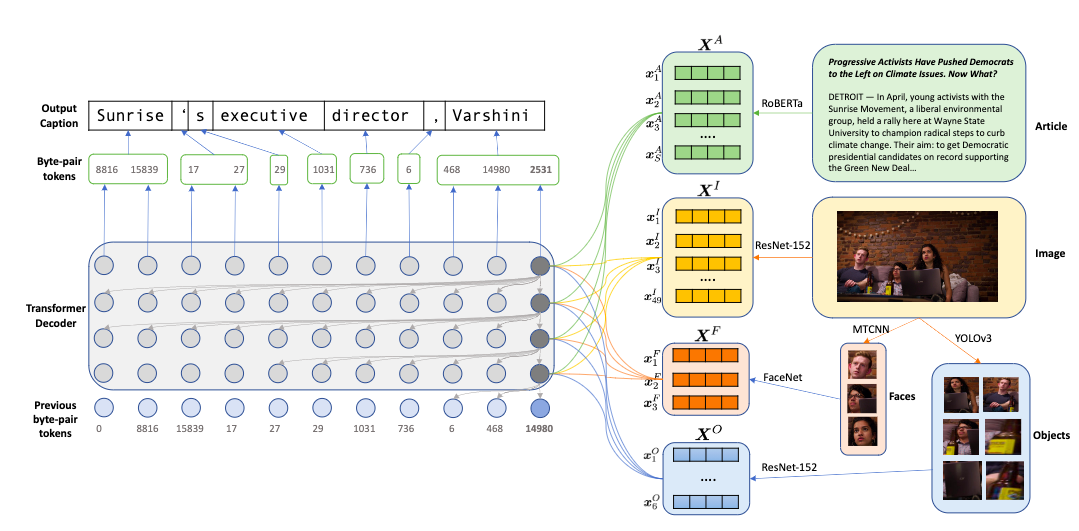
- ニュース記事に埋め込まれた画像のキャプションを生成するモデル
- 固有名に対応するため,顔・物体・単語を個別にmulti modal, multi head atentionでencode
- 一般的でない単語や新語に対応するため,byte pair encodingを使ったRoBERTaでcaption生成
- ニュース記事に埋め込まれた画像のキャプションを生成するモデル
- 先行研究と比べてどこがすごい?
- ニュースキャプションタスクで,CIDErスコアで13→54に増加するなどsotaを更新
- 技術や手法のキモはどこ?
- pre-trained encoderの集合と,decoderから構成される
- encoderは画像,顔部分画像,物体画像,記事textそれぞれについてベクトル表現を生成し,decoderはそれらにattendしながらcaptionをsub-wordレベルで生成する
- encoder
- decoder
- 今時刻までの画像,顔,物体,テキストのencodingと出力を入力し,次時刻を予測
- adaptive softmaxを使用して語彙を頻度に基づいて3クラスタに分割し,学習効率を上げる
- transformerブロック内で,過去のtokenによる条件付はdynamic convolutionを使用してself attentionを代替し効率化
- ニュースキャプションタスクのNYTimes800kデータセットを提案.既存データセットのGoodNewよりも70%大きい
- pre-trained encoderの集合と,decoderから構成される
- どうやって有効だと検証した?
- 評価指標はCIDEr, BLEU-1,2,3,4, ROUGE, METEOR, 固有名・人名・珍しい名詞のrecallとprecisionで評価
- sotaよりもほぼすべての項目で上回る結果.
- sotaのBitenモデルと比較,decoderにRoBERTaではなくLSTMやGlove埋め込み,transformerを使用した版も学習してベースラインとして比較
- transformerを使用するとLSTMより一貫して良い結果.すべての指標で.
- Glove埋め込みよりBPEのほうが良い
- 評価指標はCIDEr, BLEU-1,2,3,4, ROUGE, METEOR, 固有名・人名・珍しい名詞のrecallとprecisionで評価
- 議論はある?
- 提案データセットの平均記事長さは963単語,googNewsは451単語 (これをtext encodeする.普通のimage captionでは入力にtextがくることはない)
- 生成キャプションの平均単語数が15で,先行研究sotaの10よりも正解の18に近づいた
- 次に読むべき論文は?
- transformerを利用したimage captioing
- Xinxin Zhu, Lixiang Li, Jing Liu, Haipeng Peng, and Xinxin Niu. Captioning transformer with stacked attention modules. Applied Sciences, 8(5):739, 2018. 2
- Jiangyun Li, Peng Yao, Longteng Guo, and Weicun Zhang. Boosted transformer for image captioning.Applied Sciences, 9(16):3260, 2019. 2
- resnet152の7x7パッチの表現により,decoderが画像の異なる部分に注目できる
- Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C. Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015. 2, 3
- 使用したフレームワーク
- Matt Gardner, Joel Grus, Mark Neumann, Oyvind Tafjord, Pradeep Dasigi, Nelson F. Liu, Matthew Peters, Michael Schmitz, and Luke Zettlemoyer. AllenNLP: A deep seman-tic natural language processing platform. In Proceedings of Workshop for NLP Open Source Software (NLP-OSS), pages 1–6, Melbourne, Australia, July 2018. Associationfor Com-putational Linguistics. 6
- transformerを利用したimage captioing
- その他