ニュース記事・画像からキャプション生成,Transform and Tell
Transform and Tell: Entity-Aware News Image Captioning
- paper
- https://arxiv.org/abs/2012.00364
- Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, Wen Gao
- github
- データセット
- GoodNews, NYTimes800k
- project
まとめ
- どんなもの?
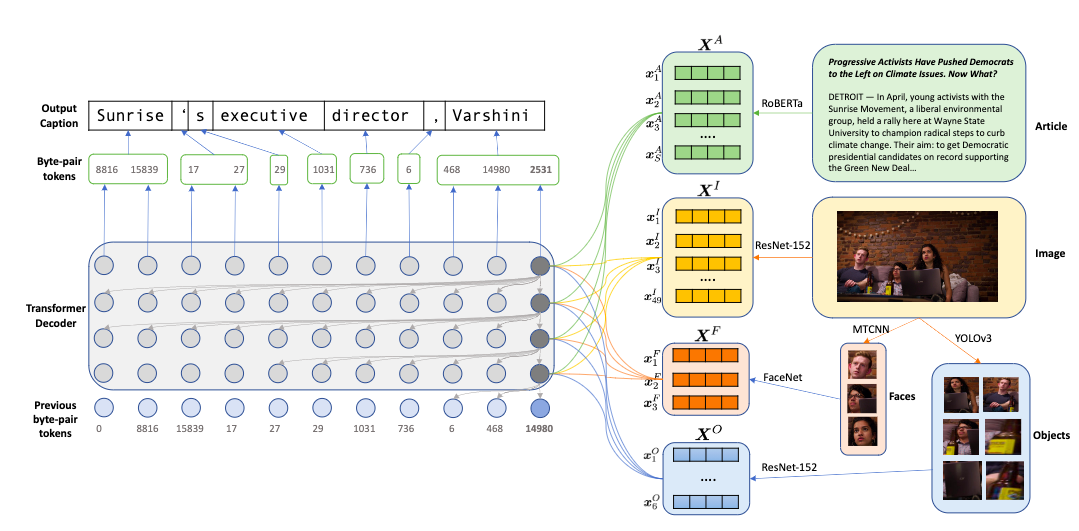
- ニュース記事に埋め込まれた画像のキャプションを生成するモデル
- 固有名に対応するため,顔・物体・単語を個別にmulti modal, multi head atentionでencode
- 一般的でない単語や新語に対応するため,byte pair encodingを使ったRoBERTaでcaption生成
- ニュース記事に埋め込まれた画像のキャプションを生成するモデル
- 先行研究と比べてどこがすごい?
- ニュースキャプションタスクで,CIDErスコアで13→54に増加するなどsotaを更新
- 技術や手法のキモはどこ?
- pre-trained encoderの集合と,decoderから構成される
- encoderは画像,顔部分画像,物体画像,記事textそれぞれについてベクトル表現を生成し,decoderはそれらにattendしながらcaptionをsub-wordレベルで生成する
- encoder
- decoder
- 今時刻までの画像,顔,物体,テキストのencodingと出力を入力し,次時刻を予測
- adaptive softmaxを使用して語彙を頻度に基づいて3クラスタに分割し,学習効率を上げる
- transformerブロック内で,過去のtokenによる条件付はdynamic convolutionを使用してself attentionを代替し効率化
- ニュースキャプションタスクのNYTimes800kデータセットを提案.既存データセットのGoodNewよりも70%大きい
- pre-trained encoderの集合と,decoderから構成される
- どうやって有効だと検証した?
- 評価指標はCIDEr, BLEU-1,2,3,4, ROUGE, METEOR, 固有名・人名・珍しい名詞のrecallとprecisionで評価
- sotaよりもほぼすべての項目で上回る結果.
- sotaのBitenモデルと比較,decoderにRoBERTaではなくLSTMやGlove埋め込み,transformerを使用した版も学習してベースラインとして比較
- transformerを使用するとLSTMより一貫して良い結果.すべての指標で.
- Glove埋め込みよりBPEのほうが良い
- 評価指標はCIDEr, BLEU-1,2,3,4, ROUGE, METEOR, 固有名・人名・珍しい名詞のrecallとprecisionで評価
- 議論はある?
- 提案データセットの平均記事長さは963単語,googNewsは451単語 (これをtext encodeする.普通のimage captionでは入力にtextがくることはない)
- 生成キャプションの平均単語数が15で,先行研究sotaの10よりも正解の18に近づいた
- 次に読むべき論文は?
- transformerを利用したimage captioing
- Xinxin Zhu, Lixiang Li, Jing Liu, Haipeng Peng, and Xinxin Niu. Captioning transformer with stacked attention modules. Applied Sciences, 8(5):739, 2018. 2
- Jiangyun Li, Peng Yao, Longteng Guo, and Weicun Zhang. Boosted transformer for image captioning.Applied Sciences, 9(16):3260, 2019. 2
- resnet152の7x7パッチの表現により,decoderが画像の異なる部分に注目できる
- Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C. Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015. 2, 3
- 使用したフレームワーク
- Matt Gardner, Joel Grus, Mark Neumann, Oyvind Tafjord, Pradeep Dasigi, Nelson F. Liu, Matthew Peters, Michael Schmitz, and Luke Zettlemoyer. AllenNLP: A deep seman-tic natural language processing platform. In Proceedings of Workshop for NLP Open Source Software (NLP-OSS), pages 1–6, Melbourne, Australia, July 2018. Associationfor Com-putational Linguistics. 6
- transformerを利用したimage captioing
- その他
物体検出結果のタグを利用して視覚-言語6タスクでSoTA更新,OSCAR
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks

まとめ
- どんなもの?
- 言語embedding,画像の物体検出特徴に加えて,画像から物体検出で得られた物体タグの系列をTransformerのSelf Attentionでvisual, language特徴をalignmentするためのアンカーポイントとして使用するVision Language Pre-train(VLP)モデル.
- 先行研究と比べてどこがすごい?
- 言語理解・生成の6個の下流タスクでSoTAを達成
- 先行研究のタグはvisualとword embedding両方に関連づいていないため,groundingが不足していたが,本研究はこれを解決
技術や手法のキモはどこ?
- OSCARが他のVLPとことなるのは入力image textペアの表現とpre training 目的関数
- 入力は単語−タグ−画像のトリプル(w, q, v)で表現する
- wは単語埋め込みの系列,
- qは検出された物体タグ(text)の埋め込み系列,
- vは画像の領域ベクトルの集合
- pre-train時の目的関数は2つ.masked token lossとcontrastive loss
- 離散token 系列をh=[w, q]として,Masked Token Loss(MTL)でpre trainする.各iterationで,hの各tokenを確率15%[MASK]トークンと置き換えてmaskする.目的はmaskされたトークンを周囲のtoken h_\iと画像特徴vから予測すること.NLLを最適化する
- 各入力tripleにつき,h'=[q, v]を画像modalityを表すとしてグループ化.wは言語modalityとする.次にqを50%の確率でデータセット内の異なるタグ系列に置き換え,polluted画像表現をサンプルする.special token [CLS]上のencoder出力は(h', w)のvision language 表現が融合しているので,二値分類器として全結合をその上に適用して,ペアが元の画像表現を含んでいる(y=1)か,pulluted onesか(y=0)を予測する
- 入力は単語−タグ−画像のトリプル(w, q, v)で表現する
- datasetは公開データセット(COCOなど)を組み合わせてimage, textペアが合計6.5million
- OSCARが他のVLPとことなるのは入力image textペアの表現とpre training 目的関数
どうやって有効だと検証した?
- image-text retreaval(サブタスク2個), image captioning, novel object captioning, VQA, GQA, natural language visual reasoning for Real, でそれぞれOSCARをfine-tuningし,結果をそれぞれのSoTAと比較.6/7個のタスクでSoTAを更新
議論はある?
- VQA, Image Retrieval, Image Captioningでタグ利用有無でablationを行い,タグを利用したほうが速く収束する
- tagはfeatureとして使ったときに改善が少ない.OSCARで行っているようにanchor pointとしては有望.(tagは視覚特徴から抽出され,言語特徴と同じ意味空間を使っているため,特徴間のalignmentをするためのアンカーポイントになる,というのが本手法の鍵.Transformerのattentionでタグ,言語,視覚特徴それぞれをペアとしたablationの結果これが示されている.デフォルトではすべてのmodalityに対してfull attentionする)
- 使用するタグの種類(語彙)は,どのデータセットでも性能改善する.
次に読むべき論文は?
- Image Captioningのsota
- [46] Zhou, L., Palangi, H., Zhang, L., Hu, H., Corso, J.J., Gao, J.: Uni ed vision-language pre-training for image captioning and VQA. AAAI (2020)
- VLP
- [2]Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., Zhang, L.: Bottom-up and top-down attention for image captioning and visual question answering. In: CVPR (2018)
- 物体検出を利用
- [46] Zhou, L., Palangi, H., Zhang, L., Hu, H., Corso, J.J., Gao, J.: Uni ed vision-language pre-training for image captioning and VQA. AAAI (2020)
- CIDEr最適化.captioningタスクでの改善に使用
- [30]Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J., Goel, V.: Self-critical sequence training for image captioning. In: CVPR (2017)
- Image Captioningのsota
その他
image captioningへのfine tuning:
- seq2seqの目的関数を使い,事前訓練と同様の方法でfine tuning
- caption.tokenの15%をランダムにマスクして,対応する出力表現を使い,マスクされたtoken idを分類する.caption tokenはその時点より以前のtokenにしか注意できない(causal設定).すべてのキャプショントークンは画像領域とオブジェクトタグに完全に注意を払いますが、その逆ではないことに注意(?
- 推論では,画像領域をencodeし,得られる物体タグ,special token[CLS]を入力とする
- 生成は[MASK]tokenをfeedすることで開始し,次時刻には前の[MASK]を出力単語と入れ替えて,その後に新たな[MASK]をappendして入力する.[STOP]tokenが出たら終了する.beam size =5のbeam searchを使用し,COCO image captioning datasetでの結果を報告
- pre train時のmask token lossによる双方向attention とは違う.OSCARをCOCOで直接fine tuneする.COCOはKarpathy split.訓練中にcaptionのトークンの15%をランダムに選んで最大3トークンをmaskする.
- OSCAR_Bではcross-entropyで40 epoch, bach size=256, 初期学習率3e^-5,CIDEr最適化を5epoch,batch size = 64, で初期学習率1e^-6
- OSCAR_Lモデルはfine tune 30epoch, b_size=128, lr=1e^-5, CIDEr 3 epoch with b_size =48, lr=1e^-6,1e^-7
- seq2seqの目的関数を使い,事前訓練と同様の方法でfine tuning
任意クラスの分類器を生成できるzero-shot転移モデルCLIP
Learning Transferable Visual Models From Natural Language Supervision

まとめ
- どんなもの?
- どの画像がどのキャプションとマッチしているかを予測する事前訓練を行うモデル.推論時に入力画像に対してキャプション部分のクラス名を変えることで任意クラスの分類器を作成できる.訓練データはwebベースの画像/テキスト4億ペアで,ImageNetの訓練データを使わずzero shotで教師ありResNet50と互角などの性能が出る
- 提案手法をContrastive Language-Image Pre-training(CLIP)と呼ぶ
- 先行研究と比べてどこがすごい?
- 30以上のデータセットでのzeroshot transferで,従来のタスク固有の教師ありモデルと互角
- 技術や手法のキモはどこ?
- image encoderとtext encoderを一緒に学習させ,(image, text)ペアの正しいペアリングを予測するように学習する.テスト時にはターゲットデータセットのクラスの説明のembeddingによってtext encoderがzero shot linear classifierを合成
- image encoderはResNet-D(Heら2019)の変種
- text encoderはRadfordら2019の変更を加えたTransformer
- lower cased BPEで語彙数を49152,計算効率のために最大系列長は76に制限.
- contrastive objectiveで学習する
- N個の(image, text)ペアがあり,CLIPはNxNの可能な(image, text)ペアのどれがバッチ内で実際に起こっているか予測するよう訓練される
- CLIPはimage encoderとtext encoderを同時訓練してマルチモーダル埋め込み空間を学習し,バッチ内のN個のrealペアのimage text embeddingのcosine 類似度を最大化し,N2-Nの正しくないペアのembeddingに対する類似度を最小化する.これらの類似度スコアの対称cross entropy lossを最小化する.
- 推論時に,A photo of a {label}のような文章の形でクラスラベルを入力することで,ラベル単体を入力するよりaccが1.3ポイント程改善
- image encoderとtext encoderを一緒に学習させ,(image, text)ペアの正しいペアリングを予測するように学習する.テスト時にはターゲットデータセットのクラスの説明のembeddingによってtext encoderがzero shot linear classifierを合成
- どうやって有効だと検証した?
- 議論はある?
- 衛星画像分類,腫瘍検出,合成物体カウント,自動運転用標識認識,距離認識,のような複雑なタスクでは性能を発揮しない
次に読むべき論文は?
- 標準化text-to-textモデル
- McCann, B., Keskar, N. S., Xiong, C., and Socher, R. The natural language decathlon: Multitask learning as ques-tion answering. arXiv preprint arXiv:1806.08730, 2018.
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever,I.Languagemodelsareunsupervisedmultitasklearners. 2019.
- テキストから画像特徴を学習する能力を示した
- Desai, K. and Johnson, J. Virtex: Learning visual rep-resentations from textual annotations. arXiv preprint arXiv:2006.06666, 2020.
- VirTex
- Bulent Sariyildiz, M., Perez, J., and Larlus, D. Learning visual representations with caption annotations. arXiv e-prints, pp. arXiv–2008, 2020.
- ICMLM
- Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., and Lan-glotz, C. P. Contrastive learning of medical visual repre-sentations from paired images and text. arXiv preprint arXiv:2010.00747, 2020.
- ConVIRT.本論文のCLIPはこれをシンプル化したもの
- Desai, K. and Johnson, J. Virtex: Learning visual rep-resentations from textual annotations. arXiv preprint arXiv:2006.06666, 2020.
- contrastive learning
- Tian, Y., Krishnan, D., and Isola, P. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
- 画像のcontrastive表現学習.predictiveより良い表現が学習できる
- Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., and Lan-glotz, C. P. Contrastive learning of medical visual repre-sentations from paired images and text. arXiv preprint arXiv:2010.00747, 2020.
- 医療画像分野でのcontrastive (text, image)の表現学習
- Tian, Y., Krishnan, D., and Isola, P. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever,I. Language models are unsupervised multitask learners. 2019.
- text encoderのtransformerに対して加えた変更
- Li,A.,Jabri,A.,Joulin,A.,andvanderMaaten,L.Learningvisual n-grams from web data. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4183–4192, 2017.
- データセットに対するzero-shot転移を最初に行った研究
- 標準化text-to-textモデル
その他
言語モデルでEOSを予測すると汎化性能悪化するらしい
The EOS Decision and Length Extrapolation
- paper
- https://arxiv.org/abs/2010.07174
- Benjamin Newman, John Hewitt, Percy Liang, Christopher D. Manning
- github
- データセット
- Dyck-(k, m), SCAN, WMT2009
- project

まとめ
どんなもの?
先行研究と比べてどこがすごい?
- 直接的に同じ研究はないが,SCANデータセット(length cutoff = 22)ではLake and Baroni, 2018のNNモデルが精度20.8に対し,本研究の-EOSは60.1を報告している.なお,同じ設定でEOS予測する+EOSモデルのスコアは18.0で,40ポイント以上の差がある.
技術や手法のキモはどこ?
どうやって有効だと検証した?
- Dyck-(k, m)実験
- Dyck-(k, m)はk種類の括弧が最大ネスト深さmをなすように構成された合成言語データセット.k=2,m=4, 6, 8を使用した.
- testデータは訓練データの10倍長い系列を使用した.hold-out validationでtrainの精度が完璧になるまで訓練する.モデルは5 * mの隠れ状態を持つ1レイヤLSTM
- 評価指標は,modelがbracketを閉じれるとき,すべての閉じ括弧の中で,どのくらいの頻度でmodelが80%以上の確率を正しい閉じ括弧に割り当てたか,というものを使う.
- すべてのケースで-EOSが+EOSを上回った.
- SCAN実験
- ロボットへの命令を示した系列を入力とし,ロボットが命令に答えて動作を行うためのコマンド列を出力するタスク.(walk left twice => TURN_LEFT, WALK, TURN_LEFT, WALK のようなもの)
- token系列の長さでtrain, testをsplitし,22ならtrainは1-22個のトークン,testは22-48個のtokenからなるデータを使うことになる.このsplitを10種類作成し,Lake and Baroni (2018)と同じLSTMを+EOSと-EOSの設定で訓練.greedy decodingでexact matchを評価
- すべてのケースで-EOSが+EOSを上回った.
- LSTM以外にtransformersでも同様の実験を行い,同様の結果を得ている
- 機械翻訳実験
- WMT2009の独->英翻訳を使用する.SCANより複雑なタスク.length=10, 15, 25で3つのsplitを作った
- hiddenの次元が500と1000の2層LSTMでencoder, decoderを作り,+EOSと-EOSを訓練.transformersでも同じ実験を行った
- 評価はBLEUスコア.(window size = 7)
- 末尾の句読点は全て取り除いているが,(文内の)lengthに関する手がかりがEOSトークンの代理として動作するので,+EOSと-EOSで性能差が小さい.-EOSのほうが汎化したと言えるほどではなかった.
- PCAの結果がtop2主成分が3%しか分散を説明していないので可視化を行っていない
- Dyck-(k, m)実験
議論はある?
次に読むべき論文は?
- Lake and Baroni (2018)
- Brenden Lake and Marco Baroni. 2018. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. In In-ternational Conference on Machine Learning, pages 2873–2882.
- SCANタスクを提案した研究と思われる.NNで20.8%を達成.
- Maxwell Nye, A. Solar-Lezama, J. Tenenbaum, and B. Lake. 2020. Learning compositional rules via neural program synthesis. ArXiv, abs/2003.05562.
- SCANでacc 100%を達成したSCAN文法の探索モデル
- OpenNMT(Klein et al., 2017)
- WMT2009のタスクではこれを使用してmodelを訓練した
- sacreBLEU(Post, 2018)
- BLEUの計算に使用したパッケージ
- Lake and Baroni (2018)
その他,所感
- +EOSが悪化するのは,testで,trainの系列長を超えた場合にということなので,納得感はある.
- 翻訳タスクでははっきりした違いが出ていないので,実用上EOS予測してもそれほど問題ないのではと思っている.
UI画像からコード生成,pix2code
pix2code: Generating Code from a Graphical User Interface Screenshot
- paper
- https://arxiv.org/abs/1705.07962
- Tony Beltramelli
- github
- データセット
- githubで公開
- project
まとめ
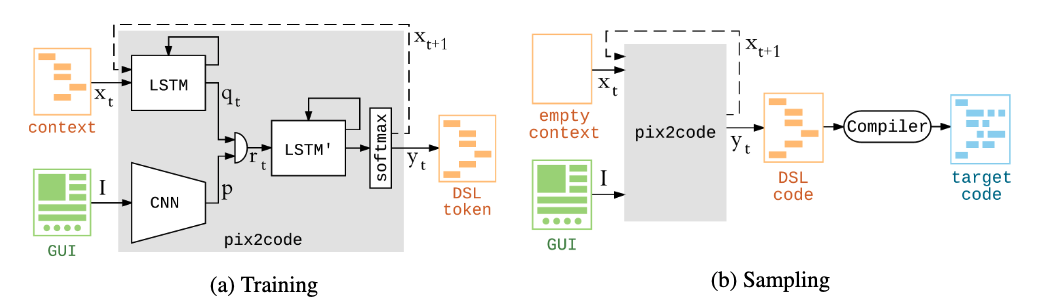
どんなもの?
先行研究と比べてどこがすごい?
- 視覚入力によるプログラム生成はまだ研究が少ない.Nguyen et al[14]はAndroid UIのリバースエンジニアリングで最も近いが,それはヒューリスティックベース.本手法は画像からend2endで学習できる
技術や手法のキモはどこ?
どうやって有効だと検証した?
議論はある?
- one-hotは語彙数が大きくなるとスケールしない
- GAN,attention, word embedding, 事前訓練,webクローリングによる大量データの使用,など改善策が沢山ある
次に読むべき論文は?
その他
- 公式実装には,webデータセットで学習した際に画像を変えても出力DSLが変化しないバグがある
- stack overflowでも報告されている(githubでissueを受け付けていない) https://stackoverflow.com/questions/62612806/i-trained-pix2code-but-it-always-output-the-same-dsl-content-no-matter-what-ima
- 公式実装には,webデータセットで学習した際に画像を変えても出力DSLが変化しないバグがある
教師なしプログラミング言語翻訳 TransCoder
Unsupervised Translation of Programming Languages
- paper
- https://arxiv.org/abs/2006.03511
- Marie-Anne Lachaux, Baptiste Roziere, Lowik Chanussot, Guillaume Lample
- github
- データセット
- Google BigQueryで抽出
- project

training
まとめ
どんなもの?
先行研究と比べてどこがすごい?
技術や手法のキモはどこ?
- モデル構造はseq2seqで,encoder, decoderにtransformer構造を採用,すべての言語(C++, Java, Python)にわたって同じモデルを1つだけ使う
- Lampleら[32]の教師なし機械翻訳の3つの原理(初期化,言語モデリング,逆翻訳)を使用して訓練
- 言語間にわたって,似た意味のsequenceが同じ潜在空間にマップされるように事前訓練する.Lample and Conneau[29]のmaskされた言語モデル目的関数の事前訓練[14]を採用(一部をマスクした系列を入力して,次のtokenを予測).プログラミング言語には,言語間をまたがって存在する共通トークン(アンカーポイントが大量にあるので,modelがcross-lingualな性質を持つようになる).異なる言語batchの系列を交互に入力する.
- seq2seqのencoderは1の事前訓練したモデルで初期化する.decoderはランダム初期化.decoderを訓練するため,Denoising Auto Encoding objectiveで訓練.入力文を[30]のrandom mask, remove, shuffleで破壊し,復元するようにdecodeさせる.encoderの出力がnoisyだったとしても妥当な関数を生成するように訓練される.encoderも入力のnoiseに強くなる(3のback-translationで有用になる)
- test時に何をすべきか教えるために逆翻訳を使用.source-to-targetモデルとtarget-to-sourceモデルを対で用意して同時に訓練する.target-to-sourceはtarget系列をsourceに戻すが,noisyなsourceが生成される.source-to-targetは弱教師ありでそのnoisy sourceからtarget文を復元する.これを互いに収束まで繰り返して同時に訓練.
- Lampleら[32]の教師なし機械翻訳の3つの原理(初期化,言語モデリング,逆翻訳)を使用して訓練
- 事前訓練では512トークンからなるソースコードの32系列のbatch,訓練では6000トークンのbatchでdenoising AEとback-translationで交互に訓練.adamと[45]の学習率スケジューラ,GPUはV100が32個.小数点精度をfloat16にしてモデルサイズを下げ,速度を上げる
- tokenizerは言語ごとに別々.コメントはソースコードに残したほうが性能が良い
- モデル構造はseq2seqで,encoder, decoderにtransformer構造を採用,すべての言語(C++, Java, Python)にわたって同じモデルを1つだけ使う
どうやって有効だと検証した?
- reference match
- 正解と完全に一致した翻訳の割合
- BLEUスコア
- computational accuracy
- 本論文が提案した評価指標.hypothesis functionが同じ入力を与えて正解と同じ結果を出力するか評価する.すべての入力に対して正解と同じ結果を返せばhypothesisは正しいと判断する.
- computational accuracyでは2つの結果の組を使う.Beam Nはビーム中に最低1つ正しい関数があった割合,Beam N - Top1はビーム中の最も高いlog-probabilityが正しい翻訳だった割合
- reference match
議論はある?
- C++ to Javaでは3.1%しか正解と完全一致しなかったが,60.9%が期待される出力を返した.さらに,BLEUによる評価は比較的平坦であり,computational accuracyとの相関がなかった.これはreference matchとbleuによる評価の問題を示している
- といっているが,表1を見ると,bleuスコアは割とcomputational accuracyと整合性があるように見える
- greedy decodingと比較して,beam searchはcomputational accuracyを大きく増加させる.Java->Pythonでbeam25の場合33.7%増加.log-probabilityが最も高いhypothesisを返すようにした場合,性能は落ちる.
- C++ to Javaでは3.1%しか正解と完全一致しなかったが,60.9%が期待される出力を返した.さらに,BLEUによる評価は比較的平坦であり,computational accuracyとの相関がなかった.これはreference matchとbleuによる評価の問題を示している
次に読むべき論文は?
- [32]
- Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. Phrase-based & neural unsupervised machine translation. In EMNLP, 2018.
- 3つの訓練手法
- Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. Phrase-based & neural unsupervised machine translation. In EMNLP, 2018.
- [29]
- [31]
- Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. In ICLR, 2018.
- cross lingual word embedding
- Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. In ICLR, 2018.
- [6]
- Mikel Artetxe, Gorka Labaka, and Eneko Agirre. Learning bilingual word embeddings with (almost) no bilingual data. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 451–462, 2017.
- cross lingual word embedding
- Mikel Artetxe, Gorka Labaka, and Eneko Agirre. Learning bilingual word embeddings with (almost) no bilingual data. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 451–462, 2017.
- [28]
- [42]
- Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1715–1725, 2015.
- BPE codesの学習
- Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1715–1725, 2015.
- [32]
その他
胸部X線データセットのドメインシフト検証,Can we trust deep learning based diagnosis? The impact of domain shift in chest radiograph classification
Can we trust deep learning based diagnosis? The impact of domain shift in chest radiograph classification
- paper
- https://arxiv.org/abs/1909.01940
- Eduardo H. P. Pooch, Pedro L. Ballester, Rodrigo C. Barros
- github
- データセット
- ChestX-ray14, CheXpert, MIMIC-CXR, PadChest
- project

まとめ
- どんなもの?
- 先行研究と比べてどこがすごい?
- 同様の研究はない
- 技術や手法のキモはどこ?
- どうやって有効だと検証した?
- 議論はある?
- CheXpertとMIMIC-CXRはピクセル輝度の分布が近いが,それ以外のデータセットは異なる
- CheXpertとMIMIC-CXRは変動が少ない.PadChestとChestX-ray14は自身のtest setが最もよく,他のデータセットでは落ちる
- ChestX-ray14のlabelerはその信頼性に疑問があり,[17]はラベルが画像の内容を適切に表していないとしている
- CheXpertとMIMIC-CXRは他2つのテストセットに対しても上手くいっている.逆は成り立たない
- ドメインシフトの影響を事前に減らすためのvalidation方法として,小さいデータセットを,モデルを利用する予定の特定のマシンから作成して,大規模データセットで事前訓練してからその小さいデータでfine-tuneすることを提案している
- 次に読むべき論文は?
- [18]
- Rajpurkar, P., Irvin, J., Zhu, K., Yang, B., Mehta, H., Duan, T., Ding, D., Bagul, A., Langlotz, C., Shpanskaya, K., et al.: Chexnet: Radiologist-level pneumonia de-tection on chest x-rays with deep learning. arXiv preprint arXiv:1711.05225 (2017)
- Chexnet.本論文で実験に使用したモデル
- Rajpurkar, P., Irvin, J., Zhu, K., Yang, B., Mehta, H., Duan, T., Ding, D., Bagul, A., Langlotz, C., Shpanskaya, K., et al.: Chexnet: Radiologist-level pneumonia de-tection on chest x-rays with deep learning. arXiv preprint arXiv:1711.05225 (2017)
- [17]
- Oakden-Rayner, L.: Exploring large scale public medical image datasets. Tech. rep., The University of Adelaide (2019), https://arxiv.org/pdf/1907.12720.pdf
- ChestX-ray14のラベルが画像の内容を表していないとしている報告
- Oakden-Rayner, L.: Exploring large scale public medical image datasets. Tech. rep., The University of Adelaide (2019), https://arxiv.org/pdf/1907.12720.pdf
- [18]
- その他