UI画像からコード生成,pix2code
pix2code: Generating Code from a Graphical User Interface Screenshot
- paper
- https://arxiv.org/abs/1705.07962
- Tony Beltramelli
- github
- データセット
- githubで公開
- project
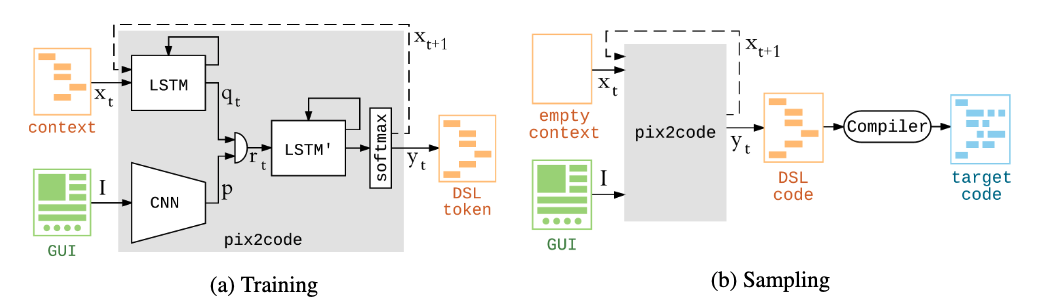
まとめ
どんなもの?
先行研究と比べてどこがすごい?
- 視覚入力によるプログラム生成はまだ研究が少ない.Nguyen et al[14]はAndroid UIのリバースエンジニアリングで最も近いが,それはヒューリスティックベース.本手法は画像からend2endで学習できる
技術や手法のキモはどこ?
どうやって有効だと検証した?
議論はある?
- one-hotは語彙数が大きくなるとスケールしない
- GAN,attention, word embedding, 事前訓練,webクローリングによる大量データの使用,など改善策が沢山ある
次に読むべき論文は?
その他
- 公式実装には,webデータセットで学習した際に画像を変えても出力DSLが変化しないバグがある
- stack overflowでも報告されている(githubでissueを受け付けていない) https://stackoverflow.com/questions/62612806/i-trained-pix2code-but-it-always-output-the-same-dsl-content-no-matter-what-ima
- 公式実装には,webデータセットで学習した際に画像を変えても出力DSLが変化しないバグがある